مدلهای زبانی بزرگ مانند GPT-4، جمنای، Llama 2 و ابزارهای مشابه، بر اساس حجم عظیمی از دادهها آموزش دیدهاند و میتوانند بهصورت خودکار پاسخ تولید کنند، ترجمه انجام دهند یا جملات را کامل کنند. اما از آنجا که این مدلها فقط بر پایهی دادههایی پاسخ میدهند که در زمان آموزش دیدهاند، ممکن است پاسخهایی قدیمی، ناقص یا غیرمرتبط ارایه دهند. برای رفع این مشکل، روشی به نام RAG یا تولید تقویتشده با بازیابی (Retrieval-Augmented Generation) مطرح شده است.
RAG به مدل کمک میکند تا پیش از تولید پاسخ، اطلاعات موردنیاز را از یک پایگاه دانش معتبر خارج از دادههای آموزشی اولیه خود بازیابی کند. به این ترتیب، بدون نیاز به آموزش مجدد، مدل میتواند پاسخهایی دقیقتر، بهروزتر و مرتبطتر ارایه دهد. در این مقاله از ایلاچت به زبان ساده با مفهوم RAG، کاربردهای آن و نحوه استفاده از آن در ابزارهای هوش مصنوعی مانند چتباتها آشنا خواهیم شد.
فهرست مطالب
RAG چیست؟
تولید تقویتشده با بازیابی یا RAG (مخفف Retrieval-Augmented Generation) روشی نسبتا نوین در هوش مصنوعی است که به مدلهای زبانی بزرگ (LLMs) کمک میکند پاسخهایی دقیقتر، بهروزتر و متناسب با زمینه تولید کنند، بدون اینکه نیاز باشد مدل از ابتدا آموزش داده شود.
مدلهای زبانی بزرگ، مانند GPT-4، بر اساس حجم عظیمی از دادهها آموزش میبینند و توانایی انجام کارهایی مانند پاسخگویی به پرسشها، ترجمه متن و تکمیل جملات را دارند. اما یک محدودیت مهم دارند: آنها فقط به دانشی دسترسی دارند که در زمان آموزش در اختیارشان بوده است. این دانش ممکن است قدیمی، کلی یا غیرمرتبط با زمینهی خاص کسبوکار شما باشد.
مثالی ساده برای درک بهتر RAG
فرض کنید یک لیگ ورزشی میخواهد چتباتی ایجاد کند که به طرفداران و خبرنگاران در مورد تاریخچه تیمها، قوانین بازی، مشخصات بازیکنان یا آمار مسابقات پاسخ دهد.
یک مدل زبانی عمومی شاید بتواند درباره تاریخچه یا ویژگیهای ورزشگاهها صحبت کند، اما بهدلیل نداشتن دادههای بهروز، نمیتواند درباره نتیجه بازی شب گذشته یا آخرین وضعیت مصدومیت بازیکنها پاسخ دقیقی بدهد. چرا؟ چون اطلاعات آموزشی مدل، زمانبر و پرهزینه است و بهراحتی بهروز نمیشود.
در مقابل، همان سازمان ورزشی به منابع مختلفی دسترسی دارد: پایگاه داده بازیکنان، آرشیو مسابقات، گزارشهای خبری و غیره. با استفاده از RAG، چتبات میتواند این اطلاعات را دریافت کند و پاسخهایی بدهد که بهروز، دقیق و مرتبط با نیاز کاربر باشد. به بیان ساده، RAG کمک میکند مدلهای زبانی پاسخهای بهتری تولید کنند.
چرا RAG اهمیت دارد؟
مدلهای زبانی بزرگ (LLM) یکی از فناوریهای کلیدی هوش مصنوعی هستند که در ساخت چتباتهای هوشمند و ابزارهای پردازش زبان طبیعی (NLP) بهکار میروند. هدف از این ابزارها، پاسخگویی دقیق به پرسشهای کاربران در زمینههای مختلف است؛ آن هم با تکیه بر منابع اطلاعاتی معتبر.
اما واقعیت این است که مدلهای زبانی، با وجود توانایی بالا، محدودیتهایی هم دارند. دادههایی که با آنها آموزش میبینند، ثابت هستند و فقط تا یک نقطهی زمانی خاص را پوشش میدهند. همین موضوع باعث میشود که پاسخهایی که ارایه میدهند، در بسیاری از موارد ناقص، نادرست یا قدیمی باشند.
چالشهای رایج مدلهای زبانی:
- زمانی که اطلاعات کافی ندارند، ممکن است پاسخ اشتباه تولید کنند.
- در شرایطی که پاسخ بهروز یا اختصاصی نیاز است، اطلاعات کلی یا قدیمی ارایه میدهند.
- گاهی پاسخ را بر اساس منابع غیرمعتبر یا غیرمرتبط تولید میکنند.
- در بعضی موارد، بهدلیل شباهت واژهها در منابع مختلف، مفاهیم را اشتباه درک میکنند.
مدل زبانی را میتوان مانند کارمند جدیدی در نظر گرفت که همیشه با اعتمادبهنفس به همهی سوالات پاسخ میدهد، اما علاقهای به پیگیری اخبار روز یا منابع موثق ندارد. چنین رویکردی ممکن است باعث کاهش اعتماد کاربران شود و طبیعتا چنین رفتاری برای یک چتبات یا سیستم هوشمند، قابلقبول نیست.
اینجاست که RAG وارد عمل میشود. این روش به مدل کمک میکند تا بهجای تکیه صرف بر دانستههای قبلی، اطلاعات مرتبط را از منابع مشخص و قابلاعتماد بازیابی کند. به این ترتیب، سازمانها کنترل بیشتری بر محتوای تولیدشده دارند و کاربران نیز درک شفافتری از منبع و منطق پاسخهای مدل بهدست میآورند.
مزایای RAG چیست؟
فناوری RAG مزایای متعددی برای بهبود عملکرد هوش مصنوعی تولیدی در سازمانها به همراه دارد.
پیادهسازی مقرونبهصرفه
توسعه چتباتها معمولا با استفاده از یک مدل پایه آغاز میشود. مدلهای پایه (Foundation Models) همان مدلهای زبانی بزرگی هستند که از طریق API در دسترساند و بر اساس دادههای عمومی و بدون برچسب آموزش دیدهاند. آموزش مجدد این مدلها برای دادههای خاص یک سازمان یا حوزه تخصصی، هم از نظر محاسباتی و هم مالی، بسیار پرهزینه است.
RAG روشی مقرونبهصرفه برای افزودن دادههای جدید به مدل محسوب میشود و استفاده از هوش مصنوعی تولیدی را برای سازمانها آسانتر و در دسترستر میکند.
دسترسی به اطلاعات بهروز
حتی اگر دادههای آموزشی اولیه یک مدل زبانی برای نیازهای شما مناسب باشد، حفظ بهروز بودن آن یک چالش بزرگ است. RAG این امکان را فراهم میکند که آخرین پژوهشها، آمارها یا اخبار به مدل منتقل شود. توسعهدهندگان میتوانند با استفاده از RAG مدل را به منابع زنده مانند شبکههای اجتماعی، سایتهای خبری یا سایر منابع بهروزشونده متصل کنند تا پاسخهایی تازه و دقیقتر به کاربران ارایه شود.
افزایش اعتماد کاربران
RAG به مدل امکان میدهد اطلاعات دقیق را همراه با ارجاع به منبع ارایه کند. خروجی میتواند شامل لینک یا ذکر منبع باشد، و کاربران در صورت نیاز میتوانند خودشان به اسناد اصلی مراجعه کنند. این شفافیت باعث افزایش اعتماد و اطمینان کاربران به سیستم هوش مصنوعی تولیدی خواهد شد.
کنترل بیشتر برای توسعهدهندگان
با استفاده از RAG، توسعهدهندگان میتوانند راحتتر چتباتهای خود را آزمایش و بهینه کنند. آنها میتوانند منابع اطلاعاتی مدل را تغییر دهند تا با نیازهای جدید یا کاربردهای مختلف سازگار شوند.
همچنین میتوانند بازیابی اطلاعات حساس را بر اساس سطح دسترسی کنترل کرده و اطمینان حاصل کنند که مدل پاسخهای مناسب ارایه میدهد. اگر مدل به اشتباه به منبع نامناسبی ارجاع دهد، توسعهدهندگان میتوانند آن را اصلاح کرده یا بهبود دهند. در نتیجه، سازمانها میتوانند با اطمینان بیشتری فناوری هوش مصنوعی تولیدی را در مقیاس وسیعتری پیادهسازی کنند.
RAG چگونه کار میکند؟
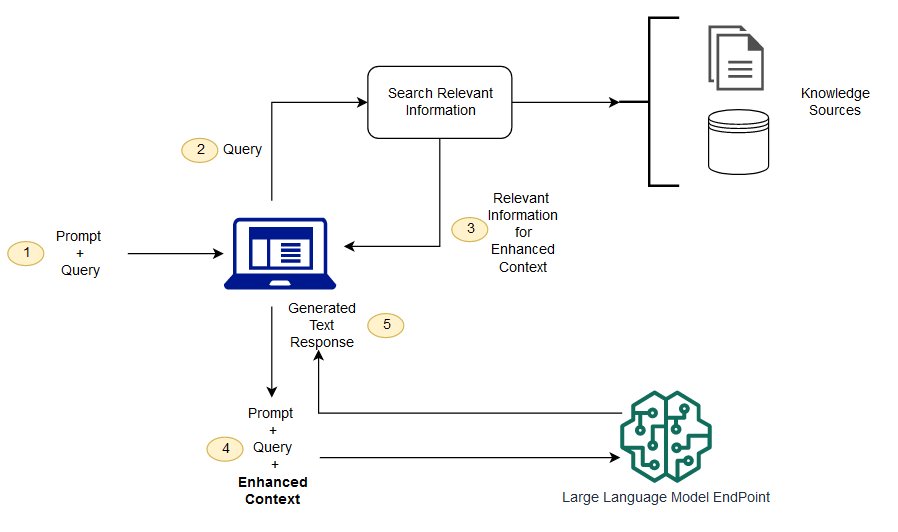
بدون استفاده از RAG، مدل زبانی بزرگ (LLM) صرفا ورودی کاربر را دریافت کرده و بر اساس اطلاعاتی که در زمان آموزش یاد گرفته، پاسخ تولید میکند. اما با استفاده از RAG، یک بخش بازیابی اطلاعات به سیستم اضافه میشود که ابتدا با توجه به پرسش کاربر، دادههای مرتبط را از یک منبع خارجی دریافت میکند. سپس، پرسش کاربر و اطلاعات بازیابیشده به مدل داده میشود و مدل با ترکیب این دو، پاسخ دقیقتر و کاربردیتری ارایه میدهد. در ادامه، مراحل اجرای RAG را بررسی میکنیم.
ایجاد دادههای خارجی
به دادههایی که خارج از مجموعه دادههای آموزشی اولیه مدل قرار دارند، دادههای خارجی (External Data) گفته میشود. این دادهها میتوانند از منابع مختلفی مانند APIها، پایگاههای داده یا مخازن اسناد بهدست آیند. فرمت دادهها ممکن است فایل، رکوردهای دیتابیس یا متنهای بلند باشد.
در این مرحله، از یک تکنیک هوش مصنوعی بهنام مدلهای تعبیهسازی (embedding) استفاده میشود که دادهها را به نمایش عددی (وکتور) تبدیل میکند و آنها را در یک پایگاه داده وکتوری ذخیره مینماید. این فرایند به ساخت یک کتابخانه دانشی منجر میشود که مدل هوش مصنوعی قادر به درک آن است.
بازیابی اطلاعات مرتبط
در این مرحله، سیستم با استفاده از تکنیک جستوجوی مبتنی بر شباهت، اطلاعات مرتبط با پرسش کاربر را پیدا میکند. ابتدا، ورودی کاربر به یک بردار عددی تبدیل میشود و با بردارهای موجود در پایگاه داده وکتوری مقایسه میشود.
برای مثال، تصور کنید چتباتی برای پاسخگویی به سوالات منابع انسانی طراحی شده است. اگر کارمند بپرسد: «چقدر مرخصی سالیانه دارم؟» سیستم اسناد مربوط به سیاستهای مرخصی و سابقه مرخصی آن کارمند را بازیابی میکند. این اسناد بهدلیل ارتباط مستقیم با سوال، به مدل برگردانده میشوند.
تشخیص ارتباط از طریق محاسبات ریاضی روی بردارهای عددی انجام میشود.
غنیسازی پرامپت ورودی مدل
در این مرحله، مدل RAG ورودی کاربر (پرامپت) را با افزودن دادههای مرتبط، غنیسازی میکند. این کار با استفاده از تکنیکهای مهندسی پرامپت (Prompt Engineering) انجام میشود تا مدل بهتر بتواند مفهوم سوال را درک کرده و پاسخی دقیقتر تولید کند.
بهروزرسانی دادههای خارجی
ممکن است این سوال مطرح شود که اگر دادههای خارجی قدیمی شوند چه باید کرد؟ برای حفظ بهروز بودن اطلاعات، لازم است اسناد و نسخه تعبیهشدهی آنها (embedding) بهصورت غیرهمزمان (asynchronous) بهروزرسانی شوند. این بهروزرسانی میتواند از طریق فرایندهای خودکار در زمان واقعی (real-time) یا پردازشهای دورهای (batch) انجام شود. این چالش در علم داده رایج است و میتوان از رویکردهای مختلف مدیریت داده برای حل آن استفاده کرد.
نمودار زیر جریان مفهومی استفاده از RAG در کنار مدلهای زبانی بزرگ (LLM) را نشان میدهد.
تفاوت RAG و جستجوی معنایی چیست؟
جستجوی معنایی (Semantic Search) به بهبود نتایج RAG کمک میکند، بهویژه زمانی که سازمانها میخواهند منابع دانشی گستردهای را به مدلهای زبانی خود اضافه کنند. سازمانهای مدرن معمولا حجم زیادی از اطلاعات را در قالب راهنماها، سوالات پرتکرار (FAQ)، گزارشهای پژوهشی، دستورالعملهای خدمات مشتری و اسناد منابع انسانی در سیستمهای مختلف ذخیره میکنند. بازیابی اطلاعات مرتبط در این مقیاس، کار دشواری است و همین مسیله میتواند کیفیت خروجی مدلهای تولیدی را کاهش دهد.
فناوری جستجوی معنایی این مشکل را حل میکند. این فناوری میتواند پایگاههای داده حجیم و متنوع را بررسی کرده و دادههای مرتبط را با دقت بیشتری استخراج کند. برای مثال، میتواند به پرسشی مانند «سال گذشته چقدر برای تعمیرات ماشینآلات هزینه شد؟» پاسخ مشخصی بدهد، نه فقط لیستی از نتایج جستجو. این پاسخ مستقیما از اسناد مرتبط استخراج میشود. توسعهدهندگان نیز میتوانند از این اطلاعات برای غنیسازی ورودی مدل استفاده کنند.
در مقابل، جستجوهای سنتی یا مبتنی بر کلیدواژه که در برخی پیادهسازیهای ساده RAG استفاده میشوند، در پروژههای نیازمند دانش عمیق، نتایج محدودی تولید میکنند. همچنین، توسعهدهندگان باید بهصورت دستی فرایندهایی مانند ساخت embedding، تقسیمبندی اسناد (chunking) و آمادهسازی داده را انجام دهند. اما فناوری جستجوی معنایی این مراحل را بهطور خودکار انجام میدهد. این فناوری بخشهای مرتبط از متن و کلمات کلیدی را بر اساس میزان ارتباط معنایی رتبهبندی کرده و کیفیت محتوای ورودی به RAG را به حداکثر میرساند.
استفاده از RAG در برنامههای چتمحور
وقتی کاربر بهدنبال دریافت فوری پاسخ یک سوال است، چتباتها یکی از بهترین گزینهها هستند. اکثر چتباتها بر اساس تعداد محدودی از هدفها (intents) آموزش داده میشوند؛ یعنی کارها یا خواستههایی که کاربر قصد انجام آنها را دارد، و صرفا به همان هدفها پاسخ میدهند. قابلیتهای RAG میتوانند چتباتهای فعلی را ارتقا دهند، زیرا به سیستم هوش مصنوعی اجازه میدهند به پرسشهایی پاسخ دهد که خارج از لیست هدفهای از پیش تعریفشده هستند، آنهم با زبان طبیعی و دقیق.
الگوی «پرسش و پاسخ» باعث میشود چتباتها یکی از بهترین موارد استفاده برای هوش مصنوعی تولیدی باشند. بسیاری از سوالها نیاز به زمینه مشخص و دقیق دارند تا پاسخ صحیحی تولید شود. از طرفی، کاربران چتبات معمولا انتظار پاسخهایی مرتبط، دقیق و بهروز دارند و این دقیقا جایی است که RAG میتواند نقش کلیدی ایفا کند. در واقع، برای بسیاری از سازمانها، چتباتها نقطه شروع استفاده از RAG و هوش مصنوعی تولیدی هستند.
برای مثال، پرسش درباره یک محصول جدید، اگر پاسخش مربوط به مدل قبلی باشد، نهتنها مفید نیست بلکه ممکن است کاربر را گمراه کند. به عنوان مثال کوهنوردی که میپرسد آیا یک پارک خاص در روز جمعه باز است، انتظار دارد پاسخی دقیق، مرتبط با همان پارک و همان تاریخ دریافت کند نه اطلاعات کلی یا قدیمی. RAG این امکان را فراهم میکند که چتباتها بتوانند چنین پاسخهایی را با دقت بالا، مبتنی بر دادههای زنده و با درک بهتر از زمینه تولید کنند.
ساخت RAG با ایلاچت
اگر به دنبال راهی ساده، سریع و بدون نیاز به دانش فنی برای راهاندازی یک سیستم هوش مصنوعی تولیدی مبتنی بر RAG هستید، ایلاچت دقیقا همان چیزی است که نیاز دارید. در ایلاچت میتوانید تنها با چند کلیک، یک چتبات قدرتمند بر پایهی پایگاه دانشی که خودتان آن را مدیریت میکنید، بسازید که به کمک فناوری RAG به سوالات کاربران یا کارکنان شما پاسخ میدهد. این پایگاه دانش بهراحتی از فایلها، اسناد، صفحات سایت یا حتی پایگاههای داده شما از طریق API ساخته میشود و در بستر ایلاچت قابل تنظیم و بهروزرسانی است.
چه بخواهید از این چتبات درون سازمان استفاده کنید (برای پاسخگویی به سوالات کارکنان، منابع انسانی، آموزش و…) یا آن را در وبسایت، فروشگاه یا اپلیکیشنتان قرار دهید تا به کاربران و مشتریان پاسخ دهد، ایلاچت بدون نیاز به کدنویسی یا زیرساخت فنی پیچیده، این امکان را در اختیار شما قرار میدهد.
اگر میخواهید یک تجربه پاسخگویی هوشمند و شخصیسازیشده را در کسبوکار خود فعال کنید، کافی است در ایلاچت ثبت نام کنید و چتبات خود را بسازید. هوش مصنوعی اختصاصی شما، فقط چند کلیک با شما فاصله دارد. ثبت نام و ساخت RAG
منابع:



